

It takes significant compute resources to harness a globe of remote sensing data, generate AI embeddings, and run the databases and API to build on demand detection models of important environmental drivers. For us, it’s essential that this process is as sustainable as possible across all dimensions: provide better performance and quality for users, reduce costs, improve engineering management of the pipeline, and fundamentally, support our ultimate mission to accelerate better management of the planet.
I’m going to dig into some of the behind the scenes sustainability improvements on patch grid generation, STAC metadata, energy transparency, and DB optimization.
Patch grid generation
While pixel-level embeddings like Google's AlphaEarth dataset are great for land classification, we continue to use patch-level embeddings. This allows us to capture features with more complex semantics that can’t be properly understood in a single pixel. To do this we use our open source implementation of ESA’s MajorTom Grid at a patch size of 320 square meters.
Both the Go and Python variants have had bug fixes and performance improvements which speed up grid generation and cell lookup. Eagle eyed contributors also pointed out a slight offset at certain latitudes that we fixed. Python versions have graduated to 1.0 and remain open source, and a Rust 🦀 and Typescript version have been added as well thanks to AI assisted coding! More on that in a future post.
STAC metadata
We continue to benchmark large Earth Foundation models on our use cases, and when we started generating 2025 embeddings at the start of this year, we switched back to the SSL4EO model from the Zhu Lab. As before, our embeddings can be found in the EarthGenome STAC catalog and remain freely available, but we’ve updated the metadata to use the emerging GeoEmbedding STAC extension developed at the CNG embeddings sprint this spring. The metadata for these embeddings is in the STAC catalog obviously, but it is also present inside the GeoParquet header. This means that now the embedding metadata and pedigree won’t be lost when the geoparquet file is downloaded.
Energy transparency
I could write an entire post on the metadata schema itself (what have I done with my life?) but one of the more interesting and topical bits of information we capture is the amount of energy used to create them. Data centers and their environmental impact are growing issues and we wanted to make sure that we were transparent about how much we contributed. I’ve been inspired by other work in the community to bring more transparency to model deployment, like Caleb and Isaac’s performance evaluations.
Each STAC record also captures information about the cloud environment, machine configuration and energy consumption for a given GeoParquet file, for example:
"emb:energy": {
"name": "NVIDIA L4",
"platform": "aws",
"energy_kwh": 0.00374258328933942,
"avg_power_w": 51.6,
"device_type": "gpu",
"max_power_w": 64.1,
"instance_type": "g6.4xlarge",
"inference_duration_s": 261.24
}
It’s difficult for us to completely and accurately capture the exact energy usage from a cloud instance due to the abstraction of the hardware and all the proprietary bits in the provider’s datacenter. The current implementation does a best-effort job of this by looking at the underlying platform, GPU/CPU and runtime duration which gives us enough information to at least understand which machine/platform combinations have the best performance.
After aggregating all of the information from this latest batch run of embeddings we see the following results:
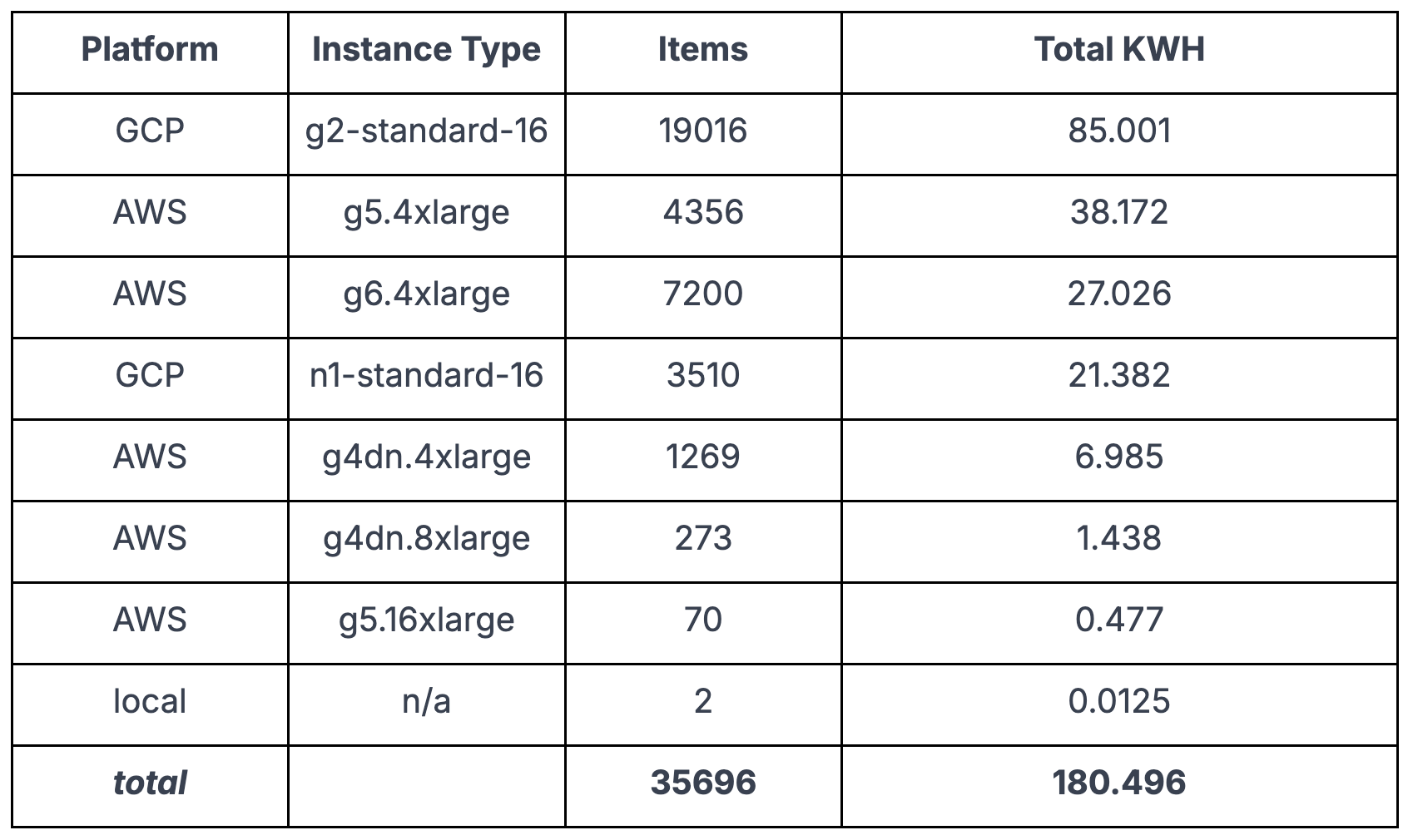
This works out to be roughly the same as about 6 days of energy usage for the typical American home. These numbers are “best effort” and I think the real energy usage is likely higher, but this is a start. Considering this is for 2 years of data with global coverage we’re comfortable with it. Especially so if we take into account all of the bespoke pixel based models that we no longer need to train directly.
DB upgrades and quantization
Our database infrastructure has seen significant improvements as well. Upgrades to Postgres 18, TensorChord 1.1.1 and PGDog are nicely counteracting the growth of data volume.
Most importantly, we now quantize embeddings from a native 32 bit float to the rabitq8 type instead of the previous halfvec 16 bit format. This means that we’re actually storing double the data at much less than double the size. Even though we’re now open to the public, we’re hoping to actually downsize our database shards as we continue to refine our architecture, and lean increasingly on DeepSearch for the heavy lifting, which accesses embeddings from GeoParquet files.
Use and reuse
We hope you’ll take our embeddings for a spin and sign up for a free Earth Index account or use them directly from S3 - and soon Source.coop! Either way, reach out and let us know how things go.
Many thanks to AWS Social Impact for continuing to support this engineering work and knowledge sharing with cloud credit grants.
Other articles

.png)


Launching Earth Index Deep Search for comprehensive planetary data
You can now train lightweight classifier models directly on the web
.png)

Mapping the planet with Earth Index is now open to everyone
Today we are proud to announce that Earth Index is open to anyone, anywhere in the world.
