Guest post by Abdul Rahman, Fulbright scholar working with Earth Genome this year.
Feedlots are a familiar feature of the Midwestern landscape, and because the cattle they house are a major source of methane emissions, they also present an important environmental challenge. As a Fulbright graduate student at the University of Pennsylvania studying policy and data analytics, I’m interested in how machine learning and spatial data can support better environmental decision-making in these exact scenarios.
Building on Ed’s recent post about the global effort with Climate TRACE to classify cattle and manure systems using Earth Index and remote sensing, my internship project at Earth Genome takes a more local approach, focusing on a narrower question: how can Alpha Earth embeddings and prior classifications used as spatial priors help precisely segment the lot and pond components of feedlot operations? By generating pixel-level segmentation masks for these facilities, I aim to better estimate their footprints and, in turn, better understand their environmental impacts.
The basic idea
This workflow builds training data from the intersection of labels and spatial priors, as shown in Figure 1. As mentioned above, spatial priors are large, pre-classified regions likely to contain feedlot operations, generated through a separate workflow and treated here as inputs. Within those constrained areas, the pipeline samples points for each class and learns to predict the class of each pixel using the AlphaEarth feature stack. The training sample includes 5,000 lot, 5,000 pond, and 7,000 other points. After training, the classifier is run across tiles during inference, and performance is evaluated using pixel-level intersection-over-union (IoU) on pixels that were not sampled for training.
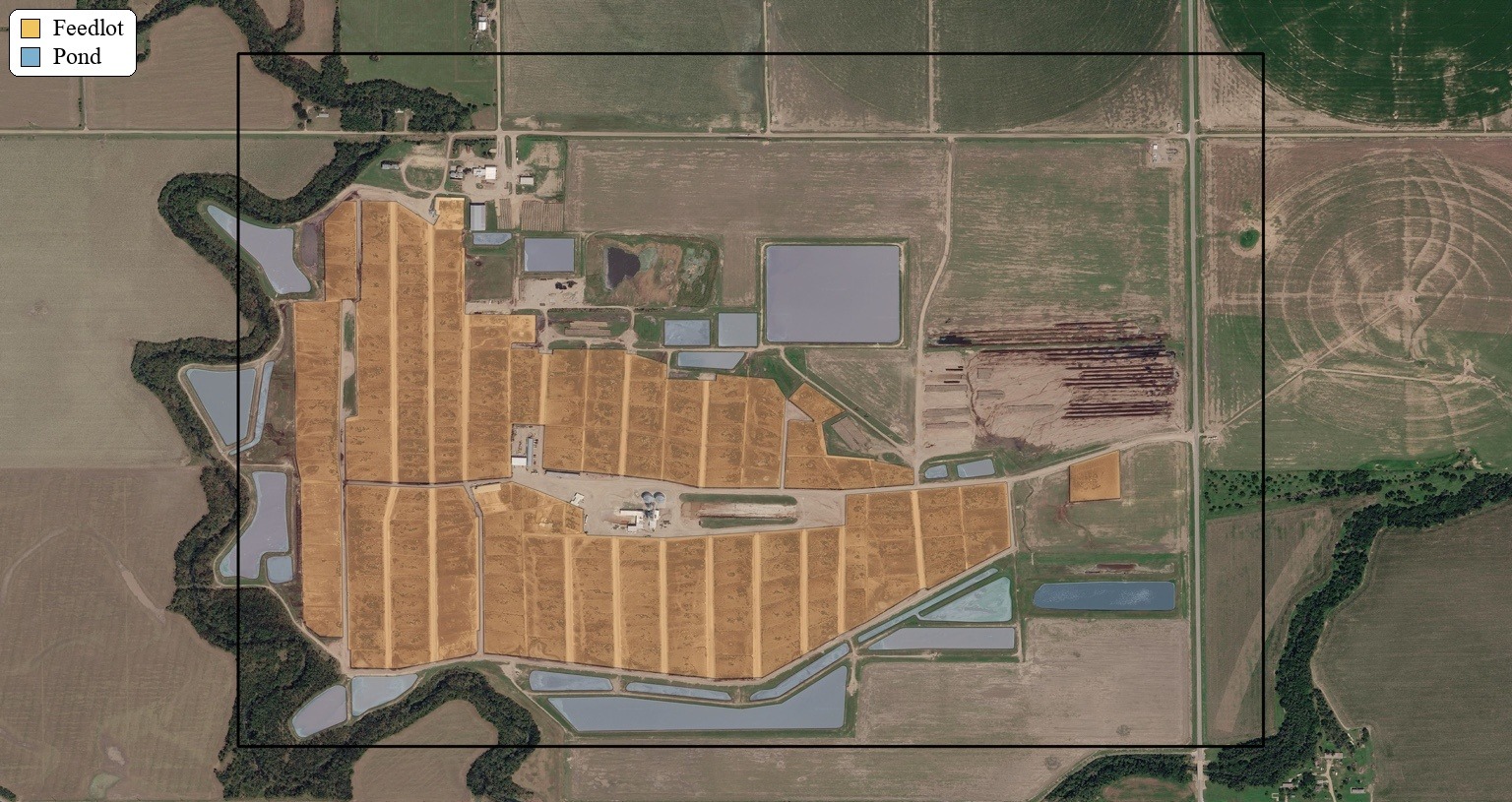
A conclusion I came to from this project is that embedding-based remote sensing workflows do not always require a large end-to-end deep learning model to produce useful results. Once the embeddings already exist, the challenge shifts to adapting those representations for a downstream task. In this case, the workflow is deliberately lightweight: pulling AlphaEarth rasters and Google Earth Engine data, sampling labeled points, extracting raster values, merging features and classes into a modeling table, training a Random Forest, running inference, and finally evaluating pixel-level IoU. A GitHub repository containing the code files can be found here.
Why spatial priors matter
The key takeaway has been the value of classified spatial priors in segmentation workflows, especially when working with embeddings. Feedlots are relatively sparse, and many of their visual characteristics overlap with numerous land-cover types. The lot area itself can resemble uprooted or cleared ground, while manure ponds are often confused with water bodies. If we sampled and predicted across the entire landscape, the problem would become both more difficult and more imbalanced. Spatial priors narrow the search space, allowing the model to focus on where the signal is most likely to exist.
This works because classifying large regions using embeddings that already encode rich spatial context is, in many ways, a simpler problem than trying to segment everything everywhere from scratch. But that convenience comes with a tradeoff. In the current workflow, priors are treated as a relatively hard boundary: each prior’s bounding box is expanded outward with a fixed positive buffer, and pixels outside that buffered region are treated as other. Only the AlphaEarth 256 × 256 tiles that intersect these processed priors are used. As a result, the pipeline inherits the incompleteness of the priors themselves. If a real lot or pond falls outside the buffered prior region, it is effectively excluded from consideration. That is one of the central tensions in this project: spatial priors make the task more manageable, but they can also clip the very features we care about and hurt recall in the process.
What worked, and what didn’t
The initial results are encouraging. On non-sampled pixels, the workflow reports an IoU of 0.999 for other, 0.498 for pond, and 0.688 for lot, with an overall mean IoU of 0.729 and a foreground IoU (pond + lot) of 0.662. The results shown in Figure 2 suggest that this prior-guided approach is already capturing a meaningful signal.
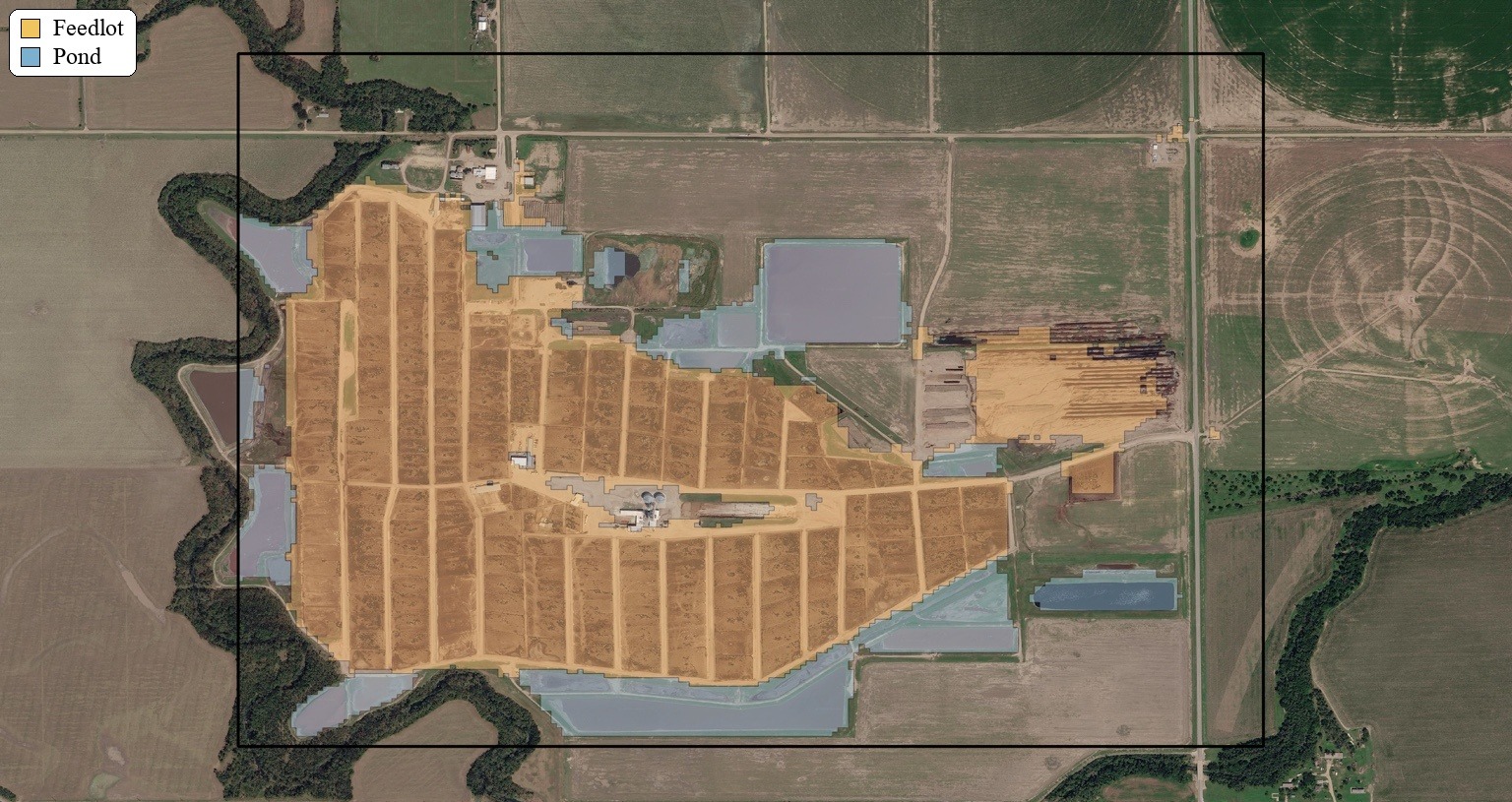
For a first-pass segmentation pipeline built around priors, sampled points, and a classical machine learning model, that is a promising result. The strongest performance is in the background class, which is not surprising: other is broader and easier to separate once the search space has already been constrained. More interesting is the performance of the lot class, which suggests that the combination of AlphaEarth features and prior-guided training is capturing a meaningful feedlot signature.
Pond is currently the weakest class. That likely reflects a combination of factors, including the hard spatial boundaries imposed by the priors and false positives around pond-like areas with similar characteristics. Arguably, the weakest link in the current pipeline is the need for labels to drive point sampling. In principle, though, those points could be sampled manually within the spatial priors, especially in cases like this where the target areas are large and visually distinct. The hard prior boundary also creates a real risk of false negatives outside the prior region.
One possible improvement would be to relax the boundary assumption by decaying prediction probabilities outside the prior boundary using a Gaussian distance-based function. Instead of treating priors as a strict cutoff, this would allow them to function more like a soft constraint, reflecting the degree of trust we place in the upstream classification workflow.
Overall, this project shows that spatial priors can make segmentation workflows far more practical, especially when paired with existing embedding stacks. But it also makes clear that the way we define and use those priors strongly shapes what the model ultimately sees and what it misses. The broader challenge, then, is not just building better classifiers, but designing priors that guide the model without blinding it to what lies just beyond the boundary.
Other articles

.png)
Engineering updates on sustainable AI at Earth Genome
Behind the scenes sustainability improvements on patch grid generation, STAC metadata, energy transparency, and DB optimization.




Launching Earth Index Deep Search for comprehensive planetary data
You can now train lightweight classifier models directly on the web
.png)