As Earth Index coverage expands, many technical issues appear that only arise at larger scales. One of the more interesting is finding an efficient and portable global grid system.
To create the embeddings that power Earth Index, we process “chips” (i.e. grid cells) of Sentinel2 images to create embeddings. In order to meaningfully compare the resulting embeddings, the cells need to be approximately similar in area size.
For example, take a look at the below image of mining detections in the Peruvian Amazon:
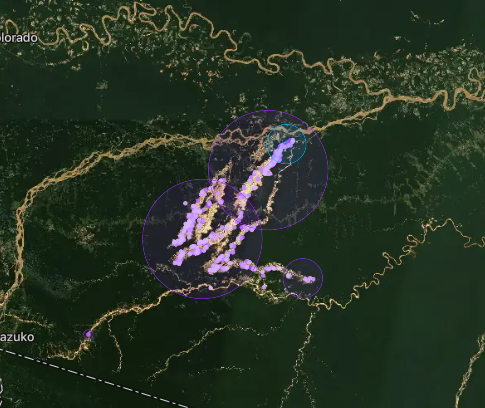
Zooming in we can see the distinct grid cells clearly.

In early iterations of Earth Index we calculated grid cells as simply offsets from the origin pixel (0,0) of the individual image we were processing. As we move from processing discrete images to a continuous global coverage, continuing to use the image context no longer makes sense.
Additionally, as we process imagery, we need to retain the bounding box geometries of the processed cells in each image. On a small scale this is not overly difficult, however as we look towards global coverage this becomes billions of geometries. Simply cataloging all those grid cells is a fairly large undertaking worthy of a decent sized database. Any code that works with embedding geometries would need query access — not only the search code, but also any supporting services like vector tiles endpoints utilized by the front end UI.
Taking all of this into account we came up with a short list of requirements for our new grid:
- The grid we select should be able to support an arbitrary cell size, ideally in meters
- Grid cells should be equal-area globally, not distorted near the poles.
- The grid should support overlapping and offsetting. This increases the chance that a particular feature of interest might be captured in a single cell.
- We are able to calculate grid cells predictably, that is, we can calculate the grid in a local context and ensure that it will properly align with other independently calculated grid segments provided the same parameters are used. While there are a few reasons for this, the most pragmatic revolves around our needs for distributed processing and potential overhead of maintaining a global reference grid.
- The last requirement — perhaps a bit tangential — is that we have a way to uniquely identify each grid cell. ID schemes are notoriously tricky to do well — all the more so without a centralized registry.
Fast forward a few weeks worth of research and experiments….
We settled on an implementation of the ESA’s MajorTom Grid with a few adaptations to the code for flexibility and ID generation. We can now create grid cells over any area with a few simple lines of code:
In Go:

And the equivalent in Python:
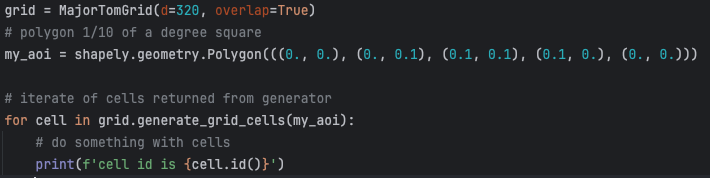
We are able to instantiate a grid and use it to generate cells over a given polygon. Each library returns grid cells containing geometries with shapely or orb geometry objects as appropriate.
But what about the IDs? Turns out a good old geohash solves this problem perfectly!
To calculate the ID of a given grid cell, we take geohash encoding of the centroid of the cell. This may seem overly simple, but Geohash IDs have several advantages:
- They are hierarchical which means that cells near each other share prefixes. This allows us to use IDs and their prefixes for all sorts of tricks like geospatial partitioning and sharding in a database.
- Geohashes are essentially base32 encoded numbers. This means that an 11 character geohash can fit inside a BigInt (64bit) type in Postgres. This means that instead of 12 bytes (11 characters + 1 byte overhead) for a text column we can substitute a BigInt column using 8 bytes instead. 4 bytes of savings might not sound like much but remember, we’re storing billions and billions or rows!
- They intrinsically maintain the geospatial context of the grid cell — the approximate value of its centroid. This means that it’s easy to find a cell’s full geometry based on its ID. The code below creates a grid, generates cells, and looks them up successfully in less than 2 milliseconds!

So, not only can we save space when storing the cell’s ID, we can also infer the whole geometry from it. This can potentially save upwards of 97 bytes per row. In a global dataset this is a savings of almost half a terabyte!
While our particular use case is somewhat niche, large embeddings datasets are becoming more and more common — with another MajorTom based set being released just the other day. We didn’t see a lot of libraries out in the open that fit our particular needs (especially in Go) so for both of these reasons we thought it might be beneficial to open source ours. Both the Python and Go versions are available on GitHub (and pypi). We’d love to hear any feedback, issues or pull requests or if you happen to use these in any of your projects.
With this grid and ID system in place we’re well on our way to scaling Earth Index to multiple years of global embeddings. Look for more blog posts about how we put this into practice inside Postgres.
Other articles

.png)
Engineering updates on sustainable AI at Earth Genome
Behind the scenes sustainability improvements on patch grid generation, STAC metadata, energy transparency, and DB optimization.




Launching Earth Index Deep Search for comprehensive planetary data
You can now train lightweight classifier models directly on the web
.png)